
30 Nov
2018
30 Nov
'18
5:53 p.m.
Ouch, what was I thinking? Mentioning a project I fundamentally can't talk in detail
about yet; not very smart.
Thus spawning a thread guaranteed to go chaotic. Sorrrry!
Also I've changed the title, since it's disrespectful to drag a deceased
person's name along with this.
I've been busy a couple of days, didn't have time to follow the thread. Still
busy, but briefly with extracts:
@ Keelan Lightfoot
More generally, an encoding standard needs to allow for ANY kind of present and future
characters, fonts and modifiers.
But even more critically, it has to allow for such things without reference to
'central standards groups'. Enforced centralism is poison. For instance Unicode,
and that vast table of symbols - that still doesn't include decent arrows (and many
other needs.) What's required is a way for any bunch of people to be able to define
their own character sets, fonts, adornments, etc, create definition files for them, and
use those among themselves. Either embedded in documents or used as referenced defaults -
both must be possible. It is easy enough to define a base encoding that allows this. And
in which legacy coding (ASCII, Unicode, etc) is one of the available defaults.
The point with embedding such capabilities in the base coding scheme, and then building
the superstructure of computing language and OS on top of that, is to achieve a scheme in
which human language and typesetting freedom is available through the entire structure.
@ Cameron Kaiser
Our problem isn't ASCII or Unicode, our problem
is how we use computers.
Markup languages are a kludge, relying on plain text to describe higher level concepts.
[snip lots]
Nice post, and I agree with all of it. This is the type of thinking needed, and in general
much like my approach. Except I'm a software and hardware designer, synthesist, and
pursue practical results. Or at least _try_ to.
Funny you mention keyboards, as that's one of the project's bootstrapping steps.
First a simulated keyboard (html & js initially) to allow free experimentation, later
an open hardware design suitable for makers, 3D printing, etc. The crappyness of
commercial keyboards is a bugbear of mine. Keyboards should be MUCH better than they are.
And last forever.
@ Grant Taylor & Toby Thain
???? bold
???? italic
???? overline
???? strike through
???? underline
???? superscript exclusive or subscript
???? uppercase exclusive or lowercase
???? opposing case
???? normal (none of the above)
This covers only a small fraction of the
Latin-centric typographic
palette - much of which has existed for 500 years in print (non-Latin
much older). Computerisation has only impoverished that palette, and
this is how it happens: Checklists instead of research.
Work with typographers when trying to represent typography in a
computer. The late Hermann Zapf was Knuth's close friend. That's the
kind of expertise you need on your team. > Surely a Chinese or Japanese based programming
language could be
> developed.
The Tomy Pyuuta has a very limited BASIC variant called
G-BASIC which has
Japanese keywords and is programmed with katakana characters (such as "kake" ...
Exactly, except it should be possible for any group (eg who speak whatever language) to
modify existing computer language to their own human dialect. With compilers and
assemblers this is not trivial, but with dictionary-based interpreters it's much
easier. The keywords and operators are all just looked up in tables to achieve effects,
and what characters or ideograms serve as the keywords are entirely flexible.
Then imagine one interpretted scripting language, that serves multiple functions: document
layout, user apps and OS scripting. And that scripting language can be phrased in any
human language, AND includes full typsetting of itself.
@ Liam Proven
There are a wider panoply of options to consider.
...
Try to collapse all these into one and you're
doomed.
Lots of great references, thanks! As for doomed... well we'll see. I think the trick
is to merely provide a mechanism for including extensible classes of 'stuff' in
the base coding. Because being rigid about the mechanics of the higher level capabilities
really is fatal. Fortunately, 'flexible extensibility' isn't so hard to do.
Especially when you have a bunch of disused legacy control codes to work with.
At 02:34 PM 28/11/2018 -0700, Jim Manley wrote:
Some computing economics history:
I'm an engineer and scientist by both education and experience,
[snip]
A theoretically "superior" encoding may
not see practical use by a significant number of people because of legacy
inertia that often makes no sense, but is rooted in cultural, sociological,
emotional, and other factors, including economics.
Yep. I'm intensely aware of the economics and inertia factors. Points:
1. The ASCII-replacement coding is just a part of a wider project.
2. It's all a private project, for fun.
3. And yet there's a convergence of developments suggesting an opportunity in near
future.
MS/Intel are bastardizing, backdooring and box-closing the Wintel platform into something
so evil even non-technical people are getting sick of it. This will continue, due to
political agenda of MS/Intel.
Simultaneously the competing Linux world is fragmenting into churn-chaos. (Complex but
irreversible reasons.)
Apple is... Apple. Becoming a platformm based mostly on virtue signalling, and
increasingly as bad as Wintel.
4. If it ever is released, it will be freeware, open hardware and copylefted. DRM
specifically banned from the platform. With many quite appealing wow-factors, several of
which will be totally killer. It is not politically possible for MS/Intel/Apple to follow
this path.
[snip]
Logic and reasoning are
simply nowhere near enough to create the conditions necessary for
widespread adoption - sometimes it's just good luck in timing (or, bad
luck, as the case may be).
Absolutely. It's mostly about politics and meme-crafting. Ref: Marx, L Ron Hubbard,
Mao, various religions, etc. Odd isn't it - so few instances of memetic weavers who
used their skills for the benefit of humankind. As opposed to those guys above, who
were all arseholes with pretty twisted objectives. Did you know L Ron Hubbard created
Scientology to win a drunken bet in a bar? Someone said "I bet you can't create a
religion!" And L Ron said "I bet I can!"
ASCII was developed in an age when Teletypes ...
Yep.
You can't blame the ASCII developers for lack of
foresight when no one in
their right mind back then would have ever predicted we could have upwards
of a trillion bytes of memory in our pockets ...
Absolutely. ASCII was a godsend at the time and I take pains to make this clear in the
proposal docs. This is a _hindsight_ refactoring.
Someone thinking that they're going to make oodles
of money from some
supposedly new-and-improved proprietary encoding "standard" that discards
five-plus decades of legacy intellectual and economic investment, is
pursuing a fool's errand.
Ha ha, I don't intend to even try to make any money from this. Other objectives.
Though, I'd probably set up a donations channel. Just in case people like it.
Even companies with resources at the level of
Apple, Google, Microsoft, etc., aren't that arrogant, and they've
demonstrated some pretty heavy-duty chutzpah over time. BTW, you won't be
able to patent what apparently amounts to a lookup table, and even if you
copyright it,
Patents and copyright are poisons that are crippling intellectual and technological
progress. The original concepts were OK, but got over-extended by greed (and still getting
worse.) Patents in particular have become a tool for big corporate suppression of any
potential competition, while copyright is used to destroy free expression. The entire
DRM/copyright legal framework should be nullified.
This project will be intentionally copyright and patent excluding. Freeware, published,
open source, open hardware, etc. Just a conformance symbol, which certifies (among other
things) that _nothing_ in the systems & software is under any kind of DRM restriction.
People buy or build such a system, they own it entirely.
This is why I can't mention details or coined terminology now.
True standards are open nowadays - the days of
proprietary "standards" are
Except that by 'open' they usually mean you can pay a lot of money for a copy of
the standard doc.
That's not what I call 'open.'
a couple of decades behind us - even Microsoft has been
publishing the
binary structure of their Office document file formats. The specification
for Word, that includes everything going back to v 1.0, is humongous, and
even they were having fits trying to maintain the total spec, which is
reportedly why they went with XML to create the .docx, .xlsx, .pptx, etc.,
formats. That also happened to make it possible to placate governments
(not to mention customers) that are looking for any hint of
anti-competitive behavior, and thus also made it easier for projects such
as OpenOffice and LibreOffice to flourish.
Typographical bigots, who are more interested in style than content, were
safely fenced off in the back rooms of publishing houses and printing
plants until Apple released the hounds on an unsuspecting public. I'm
actually surprised that the style purists haven't forced Smell-o-Vision
technology on The Rest of Us to ensure that the musty smell of old books is
part of every reading "experience" (I can't stand the current common use of
that word). At least I have the software chops to transform the visual
trash that passes for "style" these days into something pleasing to _my_
eyes (see what I did there with "severely-flawed" ASCII? Here's how you
can do /italics/ and !bold! BTW.).
Oh yes, tell me about it. 'Do it this way' bigots of all kinds. Pick any possible
thing that can be done more than one way, and there will be camps of fanatics insisting
their one way is the true way and all others are crazy.
Finding such artificial dichotomies (or n-way splits) has been a very rich source of
inspiration for holistic rethinking.
Btw, again I'll emphasize that when I say ASCII is severely flawed, I mean this in the
context of what we know now about information coding requirements, and creating extensible
systems. It was't 'severely flawed' back when it was created.
Nothing frosts me more than reading text that can't
be resized and
auto-reflowed, especially on mobile devices with extremely limited display
real estate. I'm fully able-bodied and I'm perturbed by such bad design,
so, I'm pretty sure that pages that prevent pinch-zooming, and that don't
allow for direct on-display text resizing/auto-reflow, violate the spirit
completely, if not virtually all of the letters, of the Americans with
Disabilities Act (and similar legislation outside the U.S., I imagine).
Well, there's more than that one requirement. If one wanted to capture a historical
document, the absolute image of the page(s) is a core aspect, and can't be
'reflowed'. But otoh, the text content should be accessible as a searchable and
reflowing character stream. A decent coding scheme will support both objectives
simultaneously.
Btw I'm constantly amazed by how badly tech docs are being 'digitized' even
now. Service manuals with fold out schematics, screened tonal multi-colour illustrations
etc... just endless awful digital copy fails. Meanwhile the original paper copies get
rarer and rarer, because idiots think 'those are all online now, paper copies are
obsolete', and throw them out.
@ Keelan Lightfoot
from a usability standpoint, control codes are
problematic. Either the user needs to memorize them, or software needs
to inject them at the appropriate times.
You're thinking of 'control codes' as something you type by holding down CTRL
and some other key. Yes, these are a pain and I personally hate UI's that depend on
memorising lots of them.
But strictly speaking 'control codes' are the byte codes 0x00 to 0x1F, in the
ASCII table. Most of which are now little used apart from in hardware protocols. How those
would be brought into use in an ASCII-replacement and new UI, is another topic. Sadly,
part of the area I won't talk about. Just bear in mind that this system includes new
keyboard designs, and 'things that have to be memorised' are fine for some people
but not for others (including me.)
Ha ha, even ctrl-C and ctrl-V for cut and paste are a pain, not because they must be
memorised, but because the ergonomics of distorting the fingers to type them, is horrible
for such a common action. Stuff like this...
Oh, and if you are wondering if I'm imagining some huge keyboard with even more keys,
no. Personally I use a short ('10-keyless') keyboard, and don't want to ever
have to go back to stupidly big keyboards.
In addition to crusty old computers, I also enjoy the
company of three
crusty old Linotypes. In fact, that's what got me thinking
about this
stuff in the first place.
Ah, I am intensely jealous! I wish I could find an old but working linotype. And someone
to teach me how to use it. Hot lead, yeah! (I used to cast things in lead as a child, have
done bronze casting and intend to do more.)
I have some exposure to typesetting & printing; enough to know how much I don't
know. Some articles on related topics are in-progress, but not yet posted.
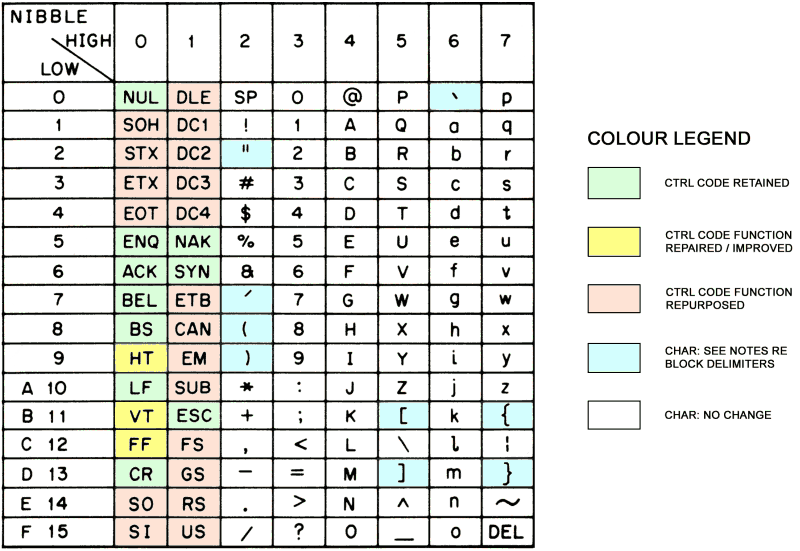
Anyway, back on topic (classic computing.) Here's an ascii chart with some control
codes highlighted.
http://everist.org/ASCII/ascii_reuse_legend.png
I'm collecting all I can find on past (and present) uses of the control codes.
Especially the ones highlighed in orange. Not having a lot of success in finding detailed
explanations, beyond very brief summaries in old textbooks.
Note that I'm mostly interested in code interpretations in communications protocols.
Their use in local file encodings not so much, since those are the domain of legacy
application software and wouldn't clash with redefinition of what the codes do, in
future applications.
And now, back to machining a lock pick for a PDP-8/S front panel cylinder lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks
Guy
{kind=link}

30 Nov
30 Nov
6:07 p.m.
New subject: WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
Yikes? and I? am complaining? ?about? trying to pick the? lock on the UNIVAC 422? anyone?
have a? key #? ?for it? That? type on that? 8S looks? ?tough...
?
Ed#?www.smecc.org?
?
?
In a message dated 11/30/2018 6:53:34 PM US Mountain Standard Time, cctalk at
classiccmp.org writes:
?
And now, back to machining a lock pick for a PDP-8/S front panel cylinder lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks

2 Dec
2 Dec
7:05 a.m.
New subject: WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
Looking at how things work, there is a new method used to pick locks that works a little
to well. It is a thing called a bump key. To make one for this cylinder lock would be
tricky. Still, it could be done.
The principle is that you bounce the tumbler pins in, while holding light tension. The
inertia of the pins pushes the pins in. As they return, the tend to catch were the would
normally turn.
I've seen one on the web demonstrated. They are quite remarkable as to how easy they
work. ( way too easy )
The idea of making one for your lock is to allow the cylinder to only turn part way
between pin angles. Once it has rotated that much, you can then measure the pin depth and
make the key.
You could make one from a blank key and use a rubber washer to improve the action.
You'd remove the piece that holds the key in the lock and make a holder block that
would allow a partial turn so that it would stop, at the right angle, between locations to
make measurements for the new key.
It is not the traditional picking method but having seen it in action makes traditional
feeling the pins obsolete.
Dwight
________________________________
From: cctalk <cctalk-bounces at classiccmp.org> on behalf of ED SHARPE via cctalk
<cctalk at classiccmp.org>
Sent: Friday, November 30, 2018 6:07 PM
To: guykd at optusnet.com.au; cctalk at classiccmp.org; cctalk at classiccmp.org
Subject: WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
Yikes and I am complaining about trying to pick the lock on the UNIVAC 422 anyone
have a key # for it? That type on that 8S looks tough...
Ed# www.smecc.org<http://www.smecc.org>
In a message dated 11/30/2018 6:53:34 PM US Mountain Standard Time, cctalk at
classiccmp.org writes:
And now, back to machining a lock pick for a PDP-8/S front panel cylinder lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks

3:57 p.m.
New subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
The Chicago Ace (tubular) lock is USUALLY easier to pick (with the right
tension wrench), since you have access to all of the pins, without having
to reach past a pin to get to another.
The commercial tools are just a tube with slots and sliders, with variable
friction. Almost trivial to make your own (as I did in High School),
although a well machined one will be a joy to use.
As such, sometimes just sliding that into the lock (WITH THE
RIGHT AMOUNT OF TORQUE) will get each pin to stop when it aligns.
Bumping seems more hassle for this.
As Dwight mentioned, picking or bumping without a pick tool that stays
aligned with the pins (like the commercial ones), opens up the additional
possibility of pins then coming back up and entering some other pin's
chamber.
The commercial tool ALSO leaves the sliders in position, so you can
"duplicate" a key from it. OR measure/read out positions to decode.
If you add calibrations to the commercial tool, then you can use it as a
temporary key for anything for which you already have the code (suc as
XX2247!)
On Sun, 2 Dec 2018, dwight via cctalk wrote:
Looking at how things work, there is a new method used
to pick locks that works a little to well. It is a thing called a bump key. To make one
for this cylinder lock would be tricky. Still, it could be done.
The principle is that you bounce the tumbler pins in, while holding light tension. The
inertia of the pins pushes the pins in. As they return, the tend to catch were the would
normally turn.
I've seen one on the web demonstrated. They are quite remarkable as to how easy they
work. ( way too easy )
The idea of making one for your lock is to allow the cylinder to only turn part way
between pin angles. Once it has rotated that much, you can then measure the pin depth and
make the key.
You could make one from a blank key and use a rubber washer to improve the action.
You'd remove the piece that holds the key in the lock and make a holder block that
would allow a partial turn so that it would stop, at the right angle, between locations to
make measurements for the new key.
It is not the traditional picking method but having seen it in action makes traditional
feeling the pins obsolete.
Dwight
________________________________
From: cctalk <cctalk-bounces at classiccmp.org> on behalf of ED SHARPE via cctalk
<cctalk at classiccmp.org>
Sent: Friday, November 30, 2018 6:07 PM
To: guykd at optusnet.com.au; cctalk at classiccmp.org; cctalk at classiccmp.org
Subject: WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
Yikes and I am complaining about trying to pick the lock on the UNIVAC 422 anyone
have a key # for it? That type on that 8S looks tough...
Ed# www.smecc.org<http://www.smecc.org>
In a message dated 11/30/2018 6:53:34 PM US Mountain Standard Time, cctalk at
classiccmp.org writes:
And now, back to machining a lock pick for a PDP-8/S front panel cylinder lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks
6:06 p.m.
New subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
Fred is probably right but it would be fun to try a bump key on these. It would be a lot
simpler to make. You just take a blank key and cut each pin location deep enough so when
fully engaged it would push the pins in about 1/16 inch. Then grind the piece that locks
in in until fully turned off. Then one would put some rubber washers on it so that it just
lifts off the pins from the washers lifting it.
One could most likely tension by hand but like Fred says, one could easily over shoot and
then have to pick it again.
Dwight
________________________________
From: cctalk <cctalk-bounces at classiccmp.org> on behalf of Fred Cisin via cctalk
<cctalk at classiccmp.org>
Sent: Sunday, December 2, 2018 3:57 PM
To: General Discussion: On-Topic and Off-Topic Posts
Subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING
KEY MFR AND KEY #
The Chicago Ace (tubular) lock is USUALLY easier to pick (with the right
tension wrench), since you have access to all of the pins, without having
to reach past a pin to get to another.
The commercial tools are just a tube with slots and sliders, with variable
friction. Almost trivial to make your own (as I did in High School),
although a well machined one will be a joy to use.
As such, sometimes just sliding that into the lock (WITH THE
RIGHT AMOUNT OF TORQUE) will get each pin to stop when it aligns.
Bumping seems more hassle for this.
As Dwight mentioned, picking or bumping without a pick tool that stays
aligned with the pins (like the commercial ones), opens up the additional
possibility of pins then coming back up and entering some other pin's
chamber.
The commercial tool ALSO leaves the sliders in position, so you can
"duplicate" a key from it. OR measure/read out positions to decode.
If you add calibrations to the commercial tool, then you can use it as a
temporary key for anything for which you already have the code (suc as
XX2247!)
On Sun, 2 Dec 2018, dwight via cctalk wrote:
Looking at how things work, there is a new method used
to pick locks that works a little to well. It is a thing called a bump key. To make one
for this cylinder lock would be tricky. Still, it could be done.
The principle is that you bounce the tumbler pins in, while holding light tension. The
inertia of the pins pushes the pins in. As they return, the tend to catch were the would
normally turn.
I've seen one on the web demonstrated. They are quite remarkable as to how easy they
work. ( way too easy )
The idea of making one for your lock is to allow the cylinder to only turn part way
between pin angles. Once it has rotated that much, you can then measure the pin depth and
make the key.
You could make one from a blank key and use a rubber washer to improve the action.
You'd remove the piece that holds the key in the lock and make a holder block that
would allow a partial turn so that it would stop, at the right angle, between locations to
make measurements for the new key.
It is not the traditional picking method but having seen it in action makes traditional
feeling the pins obsolete.
Dwight
________________________________
From: cctalk <cctalk-bounces at classiccmp.org> on behalf of ED SHARPE via cctalk
<cctalk at classiccmp.org>
Sent: Friday, November 30, 2018 6:07 PM
To: guykd at optusnet.com.au; cctalk at classiccmp.org; cctalk at classiccmp.org
Subject: WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
Yikes and I am complaining about trying to pick the lock on the UNIVAC 422 anyone
have a key # for it? That type on that 8S looks tough...
Ed# www.smecc.org<http://www.smecc.org>
In a message dated 11/30/2018 6:53:34 PM US Mountain Standard Time, cctalk at
classiccmp.org writes:
And now, back to machining a lock pick for a PDP-8/S front panel cylinder lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks
6:19 p.m.
New subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
On Mon, 3 Dec 2018, dwight via cctalk wrote:
Fred is probably right but it would be fun to try a
bump key on these.
It would be a lot simpler to make. You just take a blank key and cut
each pin location deep enough so when fully engaged it would push the
pins in about 1/16 inch. Then grind the piece that locks in in until
fully turned off. Then one would put some rubber washers on it so that
it just lifts off the pins from the washers lifting it.
One could most likely tension by hand but like Fred says, one could
easily over shoot and then have to pick it again.
How about making it with two concentric tubes; one operating, and an outer
partial one that locks to the outer notch, with a slider between the
tubes, so that you are applying tension to the inner tube, but the outer
one limits you to not making it as far as the next pin position.
But, for use as an unlocking tool, you do need to turn more than one pin
position, often as much as 90 degrees. So, though it would pick the lock,
you WOULD need to repeat.
Please let us know how it goes!
I'm a bit overdue on machining a better version of the conventional one -
calibrated pin positions, better adjustment of resistance including
solid locking of them, including being able to work with and without
detents at the standard cut depths.
Lack of necessity is the mother of procrastination!
6:33 p.m.
New subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
The idea is not to pick it open but to make a key. Once you've rotated half way
between two pins, you can remove the tool and measure the heights of the pins.
I like the idea of having a limiter sleeve on the outside to ride in the
slot.
Dwight
________________________________
From: cctalk <cctalk-bounces at classiccmp.org> on behalf of Fred Cisin via cctalk
<cctalk at classiccmp.org>
Sent: Sunday, December 2, 2018 6:19 PM
To: General Discussion: On-Topic and Off-Topic Posts
Subject: Re: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR
FINDING KEY MFR AND KEY #
On Mon, 3 Dec 2018, dwight via cctalk wrote:
Fred is probably right but it would be fun to try a
bump key on these.
It would be a lot simpler to make. You just take a blank key and cut
each pin location deep enough so when fully engaged it would push the
pins in about 1/16 inch. Then grind the piece that locks in in until
fully turned off. Then one would put some rubber washers on it so that
it just lifts off the pins from the washers lifting it.
One could most likely tension by hand but like Fred says, one could
easily over shoot and then have to pick it again.
How about making it with two concentric tubes; one operating, and an outer
partial one that locks to the outer notch, with a slider between the
tubes, so that you are applying tension to the inner tube, but the outer
one limits you to not making it as far as the next pin position.
But, for use as an unlocking tool, you do need to turn more than one pin
position, often as much as 90 degrees. So, though it would pick the lock,
you WOULD need to repeat.
Please let us know how it goes!
I'm a bit overdue on machining a better version of the conventional one -
calibrated pin positions, better adjustment of resistance including
solid locking of them, including being able to work with and without
detents at the standard cut depths.
Lack of necessity is the mother of procrastination!
6:42 p.m.
New subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
Having the sleeve to keep it from over rotating makes more sense when it has that dud pin.
You don't want to bump that pin so it would have more relief. If you over rotated,
you'd need another key with the dud pin in the new location. That would be a pain for
doing each position with a new key.
Dwight
________________________________
From: cctalk <cctalk-bounces at classiccmp.org> on behalf of dwight via cctalk
<cctalk at classiccmp.org>
Sent: Sunday, December 2, 2018 6:33 PM
To: General Discussion: On-Topic and Off-Topic Posts
Subject: Re: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR
FINDING KEY MFR AND KEY #
The idea is not to pick it open but to make a key. Once you've rotated half way
between two pins, you can remove the tool and measure the heights of the pins.
I like the idea of having a limiter sleeve on the outside to ride in the
slot.
Dwight
________________________________
From: cctalk <cctalk-bounces at classiccmp.org> on behalf of Fred Cisin via cctalk
<cctalk at classiccmp.org>
Sent: Sunday, December 2, 2018 6:19 PM
To: General Discussion: On-Topic and Off-Topic Posts
Subject: Re: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR
FINDING KEY MFR AND KEY #
On Mon, 3 Dec 2018, dwight via cctalk wrote:
Fred is probably right but it would be fun to try a
bump key on these.
It would be a lot simpler to make. You just take a blank key and cut
each pin location deep enough so when fully engaged it would push the
pins in about 1/16 inch. Then grind the piece that locks in in until
fully turned off. Then one would put some rubber washers on it so that
it just lifts off the pins from the washers lifting it.
One could most likely tension by hand but like Fred says, one could
easily over shoot and then have to pick it again.
How about making it with two concentric tubes; one operating, and an outer
partial one that locks to the outer notch, with a slider between the
tubes, so that you are applying tension to the inner tube, but the outer
one limits you to not making it as far as the next pin position.
But, for use as an unlocking tool, you do need to turn more than one pin
position, often as much as 90 degrees. So, though it would pick the lock,
you WOULD need to repeat.
Please let us know how it goes!
I'm a bit overdue on machining a better version of the conventional one -
calibrated pin positions, better adjustment of resistance including
solid locking of them, including being able to work with and without
detents at the standard cut depths.
Lack of necessity is the mother of procrastination!

6:41 p.m.
New subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
The commercial tools are just a tube with slots and
sliders, with variable
friction. Almost trivial to make your own (as I did in High School),
although a well machined one will be a joy to use.
As such, sometimes just sliding that into the lock (WITH THE RIGHT AMOUNT OF
TORQUE) will get each pin to stop when it aligns.
I had one of those tools and it ran about $70. You had to buy a separate
one for each size and pin count. Could add up. It was all pretty tight
size wise, machining it would be possible if you precision tools but I
don't think you could make one easily with a dremel grinding wheel or
anything.
I was trying to talk a friend into starting a website where you could
order tubular keys cut by robot by number but he didn't seem interested.
*shrug*
--
: Ethan O'Toole
7:06 p.m.
New subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
> The commercial tools are just a tube with slots
and sliders, with variable
> friction. Almost trivial to make your own (as I did in High School),
> although a well machined one will be a joy to use.
> As such, sometimes just sliding that into the lock (WITH THE RIGHT AMOUNT
> OF TORQUE) will get each pin to stop when it aligns.
On Sun, 2 Dec 2018, ethan at 757.org wrote:
I had one of those tools and it ran about $70. You had
to buy a separate one
for each size and pin count. Could add up. It was all pretty tight size wise,
machining it would be possible if you precision tools but I don't think you
could make one easily with a dremel grinding wheel or anything.
Having a complete set for ALL tubular locks, not just Chicago Ace, would
require a lot. Not so for the COMMON ones.
Other outside diameters are quite rare.
99+%? are 7 pin with 7.0, 7.3, 7.5, or 7.8mm center hole, and with the
Chicago Ace standard depths.
Using a 7.5mm center hole tool on a 7.3 lock requires a little more skill,
or figuring out a way to shim the center hole.
A set of 3: 7.0, 7.5, 7.8 on eBay, . . .
in the "race to the bottom", you can find the set of 3 for $20!
MORE, if you want quality.
I was trying to talk a friend into starting a website
where you could order
tubular keys cut by robot by number but he didn't seem interested. *shrug*
There already are mail-order code-cutting locksmiths
Do they get enough volume to call for automating it more than a worker
confirming the center hole size and setting the 7 depths?
7:15 p.m.
New subject: Picking tubular locks (WAS : Text encoding Babel. now PICKING LOCKS OR FINDING KEY MFR AND KEY #
On Sun, 2 Dec 2018, ethan at 757.org wrote:
I had one of those tools and it ran about $70. You had
to buy a separate one
for each size and pin count. Could add up. It was all pretty tight size wise,
machining it would be possible if you precision tools but I don't think you
could make one easily with a dremel grinding wheel or anything.
As an analogy, . . .
if you had a system that could image 8", 5.25", 3.5" diskettes, hard and
soft-sector, there would still be a FEW with further complications (such
as 3.0", 3.25", 100tpi, or edge indexed 8"), but you would be able to do
MOST of what you would want to do.
In fairness, maybe in the analogy, we would be stuck with only being able
to do soft-sector, thus admitting to existence of more numerous variants
that would need to be acknowledged.
Such a system would tend to be adequate for ALMOST everything.

30 Nov
30 Nov
6:21 p.m.
On Fri, Nov 30, 2018 at 5:53 PM Guy Dunphy via cctalk <cctalk at classiccmp.org>
wrote:
And now, back to machining a lock pick for a PDP-8/S front panel cylinder
lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks
Is that not just the standard DEC key used in *everything* (within rough
approximation) that DEC made?
- Josh
Guy

6:28 p.m.
On Fri, Nov 30, 2018, 6:21 PM Josh Dersch via cctalk <cctalk at classiccmp.org
wrote:
https://www.ebay.com/itm/DEC-PDP-8-PDP-11-Key-XX2247-Digital-PDP-8E-8I-8L-8…
On Fri, Nov 30, 2018 at 5:53 PM Guy Dunphy via cctalk
<
cctalk at classiccmp.org wrote:
For example:
And now, back to machining a lock pick for a PDP-8/S front panel cylinder
lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks
Is that not just the standard DEC key used in *everything* (within rough
approximation) that DEC made?
7:05 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
On Sat, 1 Dec 2018, Guy Dunphy via cctalk wrote:
And now, back to machining a lock pick for a PDP-8/S
front panel cylinder lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks
Are you sure that it's not an "XX2247"?
(Widely used on MOST PDP8's, and pretty much all keyed alike, unless there
were major needs to rekey to a different key)
If so, there are a number of people on the list who have them.
In fact, currently, there are TWO listings on eBay for that particular
key! ($25)
https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=x…
If you prefer, the tool that your locksmith uses is readily available,
even on eBay. there are a couple of minor variants, including different
diameters. It would seem that you can make a better quality one than most
of the cheap (Chinese) ones. (particularly if you need a rationalization
for continuing your machining of it)
https://www.ebay.com/sch/i.html?_from=R40&_trksid=p2334524.m570.l1313.T…
I made such a pick half a century ago, with no knowledge that there
already was such. At that time, they were called "UNPICKABLE". (until
you had an appropriate tool.
On some locks, there is a special "jiggling" needed, rather than "just
shove it in". And, occasionally, you need to just use it for torsion, and
feel the pins while sliding each slider in and out manually.
Once the pick is set to the lock cylinder, it is straightforward to
measure the depths. SOME duplicators can copy from the pick tool, but
some will knock sliders out of place.
Or, if you prefer, I can dig through some old posts on this list, and tell
you the depths of the cuts for XX2247. It has been widely discussed a few
years back.
--
Grumpy Ol' Fred cisin at xenosoft.com
7:23 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
Or, if you prefer, I can dig through some old posts on
this list, and tell
you the depths of the cuts for XX2247. It has been widely discussed a few
years back.
On Mon, 25 Apr 2011, Ethan Dicks wrote:
1 - 0.0155"
2 - 0.0310"
3 - 0.0465"
4 - 0.0620"
5 - 0.0775"
6 - 0.093"
7 - 0.1085"
8 - 0.1240"
Meaning that the XX2247 key would have depths (in the order you
describe) of 5-1-7-3-7-5-7
Given the "5-1-7-3-7-5-7", a locksmith with a tubular "code cutter"
can
make a key. Most tubular key machines can be used to "code-cut"
But, YES, a prior owner might have removed the lock at some point, and
deliberately rekeyed it to different cuts than it came from DEC with.
Not likely, but possible, particularly in some college CS departments,
where lots of students have XX2247 keys.
7:53 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
At 07:23 PM 30/11/2018 -0800, you wrote:
How come there are 8? The lock only has 7 pins.
Also which is pin 1 and which direction do they number?
I just assigned a start and direction randomly on my photo
http://everist.org/NobLog/pics/20181104/20181124_1741.jpg
Or, if you
prefer, I can dig through some old posts on this list, and tell
you the depths of the cuts for XX2247. It has been widely discussed a few
years back.
On Mon, 25 Apr 2011, Ethan Dicks wrote:
> 1 - 0.0155"
> 2 - 0.0310"
> 3 - 0.0465"
> 4 - 0.0620"
> 5 - 0.0775"
> 6 - 0.093"
> 7 - 0.1085"
> 8 - 0.1240" {kind=link}
> Meaning that the XX2247 key would have depths (in
the order you
> describe) of 5-1-7-3-7-5-7
How do you derive those? 2 x "5" and 3 x "7" but there are no such
repeats in the measurements.
Given the "5-1-7-3-7-5-7", a locksmith with a tubular "code cutter"
can
make a key. Most tubular key machines can be used to "code-cut"
But, YES, a prior owner might have removed the lock at some point, and
deliberately rekeyed it to different cuts than it came from DEC with.
Not likely, but possible, particularly in some college CS departments,
where lots of students have XX2247 keys.
They'd have to have removed the securing pin somehow, and that has never happened to
these locks.
Guy

8:37 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
How come there are 8? The lock only has 7 pins.
Also which is pin 1 and which direction do they number?
There are 8 possible depths, as Ethan listed.
The lock has seven pins, with the depth indexes Ethan listed.
Conventional pin numbering is to look into the lock, number from 1 CW
starting to right of index (roughly one o'clock).
De
9:03 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
At 11:37 PM 30/11/2018 -0500, you wrote:
Ah, sorry, lacking the context of the 2011 post I missed that. Didn't spot that
those numbers were an evenly increasing series, due to the variable digits length.
Ha ha, and an instinctive tendency to skim over all inch measurements because I loathe
imperial units.
I knew keys have standard cut depths, just assumed those numbers were actual
measurements of cut depths.
How come there
are 8? The lock only has 7 pins.
Also which is pin 1 and which direction do they number?
There are 8 possible depths, as Ethan listed.
The lock has seven pins, with the depth indexes Ethan listed. Conventional pin numbering is to look into the lock,
number from 1 CW
starting to right of index (roughly one o'clock).
So I happened to guess right about that.
http://everist.org/NobLog/pics/20181104/20181124_1741.jpg
8:38 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
Or, if you prefer, I can dig through some old posts on
this list, and tell
you the depths of the cuts for XX2247. It has been widely discussed a few
years back.
On Mon, 25 Apr 2011, Ethan Dicks wrote:
> 1 - 0.0155"
> 2 - 0.0310"
> 3 - 0.0465"
> 4 - 0.0620"
> 5 - 0.0775"
> 6 - 0.093"
> 7 - 0.1085"
> 8 - 0.1240" How come there are 8? The lock only has 7 pins.
Those are not the depths of this key. Otherwise, it would just be a ramp!
Those are the "standard" depths for the different key cuts on Ace locks.
I think that those are the OFFICIAL depths. Expect a little variance.
(as shown in the measurements listed below)
Lock manufacturers have a very limited number of different depths. in
this case 8 different depths. The "key code" is a list of the depths
used on a given key. Then, each combination is given a totally arbitrary
number, in this case "XX2247". An arbitrary number is used, rather than
the depths, so that the number can be stamped on the key, but somebody
looking at the key and reading the number won't be given the actual
depths, without having to measure.
A locksmith will look up that arbitrary number in a "code book" (now
usually online), which will use that arbitrary number as an index into a
table, and give back the specific keyblank, and the list of cuts. In this
case, looking up "XX2247" gives back "Ace tubular blank, cuts: 5, 1, 7, 3,
7, 5, 7" Each manufacturer has their own names for the same blanks, such
as "Ilco 1137"
The locksmith then looks up "depth and spacing" for that line of lock,
which tells him how far apart the pins are, and what the standard depths
are. (Q: "How deep should a # 5 cut be?" A: 0.0755")
On your HOUSE key, for example, there will probably be 5 or 6 cuts, each
of which will be one of 10 possible depths.
House keys instead of an arbitrary number will often have the depth
numbers stamped on the key.
"Depth and spacing" tells how far from the stop each of those cuts will
be, and what the standard depths are for that brand/model of lock.
There will usually be 7 cuts. Each one of which can any of those 8
possible depths.
Thus,
5-1-7-3-7-5-7
means one pin at depth #5 (0.0775"),
followed by the next pin being at depth #1 (0.0155"),
then a pin at depth #7 (0.1085"),
then a pin at depth #3 (0.0465"),
then another pin at depth #7,
then another pin at depth #5,
then another pin at depth#7
After you cut your key, stamp "XX2247" on it, so that you will know which
of your keys is the one for the PDP8.
Here's another post with less assumption of locksmith terminology:
On 25/04/2011 04:37, Vincent Slyngstad wrote:
> Patrick is correct -- there appear to be 7 cut positions, one of which
is
> actually uncut.
> Looking down the barrel of the key with the tab in the 12:00 position,
and
reading
clockwise, I measure approximately 0.8", 0.0", 0.11", 0.44",
0.11", 0.8", and 0.11".
You've apparently misplaced the decimal point :-)
A 0.8" cut, which is
over
3/4", would be longer than the key's tube...
outer
Actually, rechecking this with the 10x magnifier
and reticle (more
accurate) gives right at 1mm, 2mm, and 2.6mm for the 3 depths
of cut. (That's 39, 79, and 102 mils).
Here's what I got from two original XX2247 keys:
tube OD 0.377" (9.58mm), tube ID 0.310" (7.87mm).
The cuts are arranged in 7 out of 8 evenly-spaced positions around the circumference of the tube; the eighth position is
occupied by a
rectangular-section key approx 1.5mm wide, and 1mm deep inside the tube,
about 1.3mm high on the outside. The outside part of this key is short,
extending from approx 0.8mm from the end of the tube to about 3.6mm
back,
while the inside part extends almost the full length,
from about 0.8mm
inside.
The cut depths, clockwise from the first position, looking into the open
end with the key at the "twelve 0'clock" position are:
Key 1 Key 1 Key 2 Key 2
0.0770" 1.94mm 0.0785" 1.95mm
0.0150" 0.37mm 0.0155" 0.39mm
0.1055" 2.68mm 0.1070" 2.72mm
0.0435" 1.13mm 0.0455" 1.13mm
0.1075" 2.72mm 0.1085" 2.74mm
0.0780" 1.96mm 0.0785" 1.98mm
0.1075" 2.72mm 0.1095" 2.77mm
These are actual measurements from a depth micrometer. As you can see
if you
do the conversions, it's not easy to get
consistent results; the ends of
the
keys aren't perfectly flat.
Key 1 has "Chicago Lock Co", "ACE" and "DO NOT DUPLICATE"
stamped on it
(the
last in quite small letters). Key 2 looks older but
has the same
legend,
slightly differently arranged.

8:47 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
On 11/30/2018 09:53 PM, Guy Dunphy via cctalk wrote:
How come there are 8? The lock only has 7 pins.
Those are the 8 possible DEPTHS of the grooves cut into the key.
So, that gives a possible combinations of 8 to the 7th
power, I think.
These depths correspond (with an offset) to the lengths of
the tumblers (pins) in the lock.
So, if you know what the length of a tumbler is, you can add
the offset and figure out what depth groove to cut in the key.
Jon
9:15 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
On Fri, 30 Nov 2018, Jon Elson via cctalk wrote:
Those are the 8 possible DEPTHS of the grooves cut
into the key.
So, that gives a possible combinations of 8 to the 7th power, I think.
These depths correspond (with an offset) to the lengths of the tumblers
(pins) in the lock.
So, if you know what the length of a tumbler is, you can add the offset and
figure out what depth groove to cut in the key.
No, they are the depths of the grooves cut into the key.
The low numbers are a shallow cut.
Sometimes, people mistake the #1 cut for not being cut.
Although the combinations are 8^7, often a cut that is one off will still
work, so there are fewer usable combinations.
And in a conventional lock (non-tubular), it is a BAD idea to have the
deepest cut right near the bow (handle), or the key will break/wear out
prematurely. And some lock companies advise against having an extreme
difference between adjacent cuts. 1,9,1,9,1 will be hard to get in and out
of the lock. And, some lock companies pick patterns of only having even
number cuts for some positions and only odd numbers for some others.
7:41 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
At 07:05 PM 30/11/2018 -0800, you wrote:
On Sat, 1 Dec 2018, Guy Dunphy via cctalk wrote:
I wouldn't know. There are few retro-tech resources here in Australia, and I only
found and joined this list in Aug this year.
It very likely is. Ha ha, this is funny.
And now, back to machining a lock pick for a
PDP-8/S front panel cylinder lock.
http://everist.org/NobLog/20181104_PDP-8S.htm#locks
Are you sure that it's not an "XX2247"? (Widely used on MOST PDP8's, and pretty much all
keyed alike, unless there
were major needs to rekey to a different key)
If so, there are a number of people on the list who have them.
In fact, currently, there are TWO listings on eBay for that particular
key! ($25)
https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=x…
Heh. and one of them from Australia too. Pity I didn't know that a week ago.
$25 if I can't pick it myself. Minus what the locksmith will charge to make a key
given pin depths from my pick. We'll see.
If you prefer, the tool that your locksmith uses is
readily available,
even on eBay. there are a couple of minor variants, including different
diameters.
Yeah I did know this. Though a quick Aliexpress search failed to find one.
And I didn't want to wait the extra several weeks for shipping from China.
It would seem that you can make a better quality one
than most
of the cheap (Chinese) ones. (particularly if you need a rationalization
for continuing your machining of it)
Yes, yes, I do. x_x
Partly it was that I really had been getting annoyed with myself for not having
the dividing head set up yet. Needed for other things including gear cutting.
This was just 'adequate incentive.' Now it's working I will be having some
fun with it.
Anyway this makes for a funny aside on the web story.
Nice. Definitely going to buy one. I wonder what was wrong with my search terms before?
I made such a pick half a century ago, with no
knowledge that there
already was such. At that time, they were called "UNPICKABLE". (until
you had an appropriate tool.
On some locks, there is a special "jiggling" needed, rather than "just
shove it in". And, occasionally, you need to just use it for torsion, and
feel the pins while sliding each slider in and out manually.
This is what I expect to be doing.
Once the pick is set to the lock cylinder, it is
straightforward to
measure the depths. SOME duplicators can copy from the pick tool, but
some will knock sliders out of place.
Pins on mine will be individually solidly lockable, for that reason.
Or, if you prefer, I can dig through some old posts on
this list, and tell
you the depths of the cuts for XX2247. It has been widely discussed a few
years back.
If I can't pick it easily I'll ask.
Guy
9:17 p.m.
New subject: PDP8 key (Was: Text encoding Babel.
> Once the pick is set to the lock cylinder, it is
straightforward to
> measure the depths. SOME duplicators can copy from the pick tool, but
> some will knock sliders out of place.
On Sat, 1 Dec 2018, Guy Dunphy wrote:
Pins on mine will be individually solidly lockable,
for that reason.
While you are at it, calibrate them, so that it is easy to read out the
cut numbers.

7:35 p.m.
It was thus said that the Great Guy Dunphy via cctalk once stated:
Anyway, back on topic (classic computing.) Here's an ascii chart with some
control codes highlighted.
http://everist.org/ASCII/ascii_reuse_legend.png
I'm collecting all I can find on past (and present) uses of the control
codes. Especially the ones highlighed in orange. Not having a lot of
success in finding detailed explanations, beyond very brief summaries in
old textbooks.
Note that I'm mostly interested in code interpretations in communications
protocols. Their use in local file encodings not so much, since those are
the domain of legacy application software and wouldn't clash with
redefinition of what the codes do, in future applications.
I've found this page:
http://www.aivosto.com/articles/control-characters.html
to be helpful in describing all the control codes as defined by ANSI (the C0
set from 0x00 to 0x1F and 0x7F) and by the ISO (the C1 set from 0x80 to
0x9F). I also found reading the ECMA-48 standard to be helpful for the C1
set as well (as well as understanding web pages that supposedly describe so
called ANSI terminal codes, which are really ECMA-48 codes).
-spc
2667
days inactive
2669
days old
23 comments
10 participants
participants (10)
-
 cisin@xenosoft.com
cisin@xenosoft.com -
 couryhouse@aol.com
couryhouse@aol.com -
 derschjo@gmail.com
derschjo@gmail.com -
 dkelvey@hotmail.com
dkelvey@hotmail.com -
 drb@msu.edu
drb@msu.edu -
 elson@pico-systems.com
elson@pico-systems.com -
 ethan@757.org
ethan@757.org -
 glen.slick@gmail.com
glen.slick@gmail.com -
 guykd@optusnet.com.au
guykd@optusnet.com.au -
 spc@conman.org
spc@conman.org