
30 Sep
2009
30 Sep
'09
11:59 a.m.
Jan-Benedict Glaw wrote:
Until now, scanning documents was mainly about
conserving the paper
and being able to share it without snail-mailing around the stuff,
which always also contains the danger of loosing it. But we can now
really polish the stuff. That's /not/ a substitute for Bitsavers et
al.--we need them. The PDFs over there are a perfect format for
archiving the scanned pages. But we'd place generated PDFs next to
them, containing real Table of Contents, biblopgraphy entries and
possibly even Indices, among the OCRed text.
It all stands and falls with the quality of the printed document which
was scanned. I have for example manuals for one of my systems (from east
germany) which where printed really bad. Also the paper was such a bad
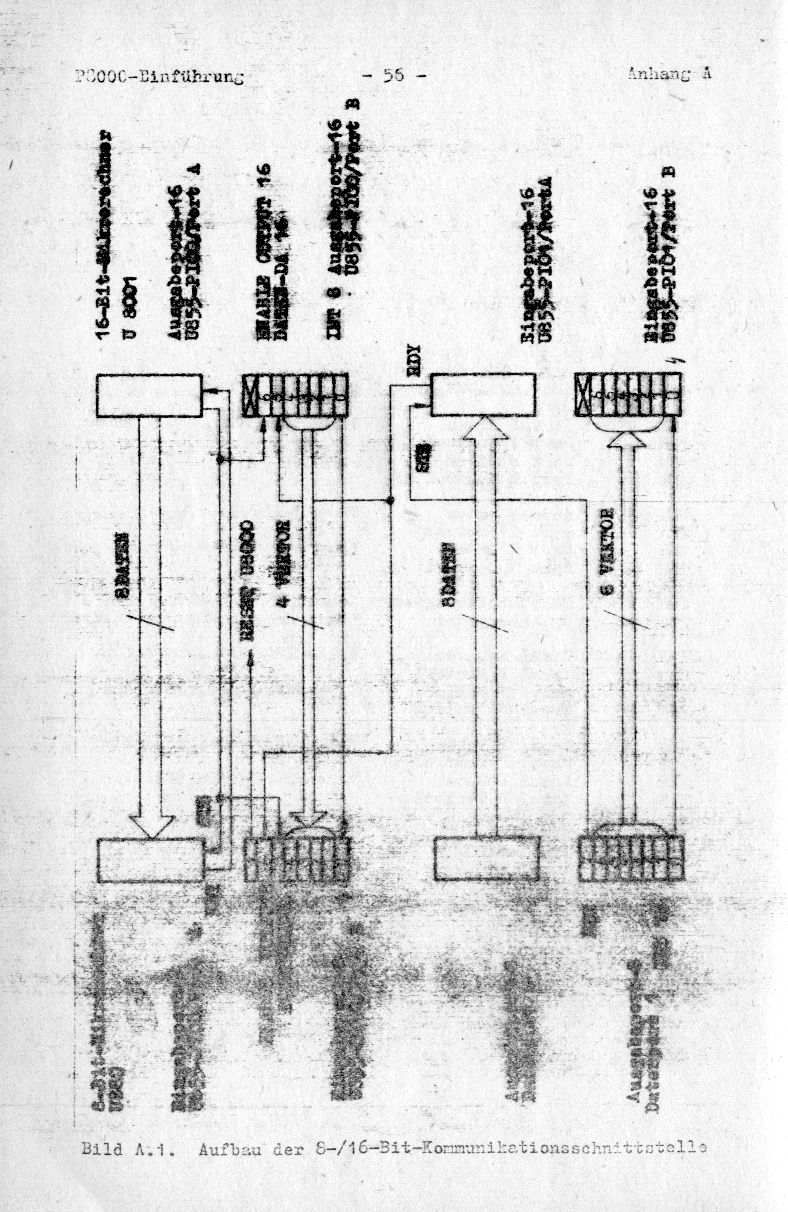
quality - it became extremly yellow now. One example (if you care):
http://files.pofo.de/066.png
http://files.pofo.de/056.png
I don't thinkthat there is any OCR Software which can cope with that ;)
Because I hate it not being able to search through documents (thats why I
like online manuals - full text search) I ended up transcripting the
manuals and invested a massive amount of time in that.... ;)
Check out pages 58 and 68 in that:
http://pofo.de/P8000/notes/books/Einfuehrung_in_die_Software/1986_12/Einfue…
And the whole pdf is smaller than a single png (I know png is not the
format which should be used, the original images are saved as TIFF);)
--
Oliver Lehmann
http://www.pofo.de/
http://wishlist.ans-netz.de/
{kind=link}
{kind=link}