

will be having some extra brochures for plated memory from Memory systems in El Suguendo Calif. Available soon
by couryhouse@aol.com
7 years, 6 months
- 1
- 0


PDP-8/e/f/m Front Panel Knob Wanted (also general information)
by mosst@SDF.ORG
7 years, 6 months
- 2
- 1








Fwd: [rescue] Sun2/120 SunOS 3.2 suntools movie (was: advise on Sun2 disk install)
by lproven@gmail.com
7 years, 6 months
- 10
- 16








sun model 47. code 4/40 does it have the nvram with battery?
by couryhouse@aol.com
7 years, 6 months
- 7
- 21





sun model 47. code 4/40 does it have the nvram with battery?
by michael.99.thompson@gmail.com
7 years, 6 months
- 2
- 1




selling rare Intel vintage ceramic gold chips C 4004, 4002, 4003, 8008 collectible
by cpl160@gmail.com
7 years, 6 months
- 1
- 0


Tektronix 6800 Board Bucket and 4051 Working Together Video
by vintagecomputer@bettercomputing.net
7 years, 6 months
- 2
- 1


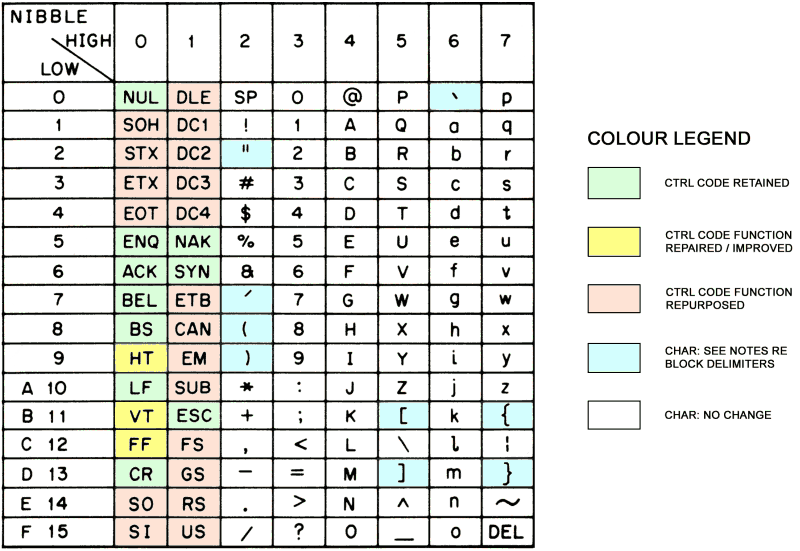
Text encoding Babel. Was Re: George Keremedjiev (off-list)
by cctalk@gtaylor.tnetconsulting.net
7 years, 6 months
- 1
- 0

NVRAM resuscitation (Was Re: SPARCstation 20 with SCSI2SD)
by technoid6502@gmail.com
7 years, 6 months
- 8
- 7

{kind=link}
{kind=link}
{kind=link}

34 pin card edge male to male biscut (wafer? adapter?)
by wh.sudbrink@verizon.net
7 years, 6 months
- 1
- 0